As developers working with Ethereum, we all know that the Ethereum Layer1 (L1) isn’t very scalable, and that’s what Layer 2 (L2) projects like Boba, Optimism, zkSync etc are committed to address and resolve in their own way.
Of course, there are several approaches to scaling - on-chain approaches like Sharding parallelizes execution by splitting the network into multiple shards. And the L2 approach takes transaction execution off-chain, using the L1 as a settlement layer through rollups or other techniques.
But here’s the thing about scaling. Over time, there’s always more demand for scale than any one solution to the problem can provide. Such is the tyranny of distributed systems!
That means an L2’s job is never done, or in general any solution for scalability is not truly complete. As is the case, the community is always looking for better ways to increase throughput and reduce latency to meet the ever-increasing demand of projects spanning the internet that need transaction finality across many organizations without sacrificing performance or reliability.
In this article we are going to get into some approaches that could push the boundaries of scalability even further, including some new methods that can be considered - specifically addressed around a single bottleneck. We will also try and weigh the pros and cons of each, to identify the most promising path forward.
Breaking the Bottlenecks
Scaling one part of a system without scaling the bottlenecks around it doesn’t get you far. While some of the more prominent reasons that limit scalability are consensus and propagation of messages (in turn the block size and time), the Ethereum Virtual Machine (EVM) is itself, in its core, a crucial limiter of scale. And, since several L2s would still want to utilize and maintain EVM compatibility/equivalence to replicate L1 user experience - they also inherently need to, and are more suitable for finding ways to get around this bottleneck.
So the natural question is - what exactly is this bottleneck and how do we get around this?
Amping Up the EVM
Y(S, T)= S'
Ethereum is a state machine, and the EVM executes transactions sequentially, one by one. It doesn’t execute other transactions until the execution of the current transaction is completed and the resulting state is computed. This is to avoid state/storage collisions and preserve atomicity of transactions. In other words, this ensures that each transaction is a self-contained, atomic unit of operation that changes the system’s state without interference from or interference to any other concurrent transactions. The execution, however, is still sequential, even with a set of completely independent transactions, because the EVM isn’t designed to be able to execute them at the same time.

Despite this being a fundamental feature, it remains a bottleneck for the performance of the network and can limit the throughput of Ethereum or any EVM chain.
Especially for an L2 where other limitations to scalability like consensus(and message propagation) might not exist, serial execution can turn out to be a more pronounced limitation. Additionally, the L2 as an execution layer for the L1, could be an easier and more suitable ground for implementing approaches to go around the bottleneck and scale maximally.
This brings in the need for parallel execution of transactions, and more so, in an L2 context.
We can think of parallel execution to be possible at two levels:
Parallel at the transaction level - treat each transaction as the smallest unit for parallelization and execute them on multiple threads.
Parallel at the opcode level - treat each operation as the smallest unit and parallelize opcodes, memory access, etc for multiple transactions.
While parallelizing at the transaction level is relatively straightforward and could produce considerable throughput improvements, parallelizing at the opcode level will attain maximum scalability. However, the latter approach is inherently more complex. We will focus on the first approach to begin with, and discuss it throughout the rest of the article.
Long Run Solutions
If we further narrow it down, storage access is where the EVM spends most time while executing a transaction. And when executed sequentially, it represents a significant portion of the overall execution time. Optimizing storage access, hence, could be an important step in enabling parallel execution.
At the same time, much of Ethereum’s ongoing research efforts have been on statelessness, witnesses, and light clients, which could enable pre-fetching or optimizing storage accesses. Furthermore, Sharding would split the network into multiple smaller networks (shards), and would theoretically parallelize execution with the design. Things would be easier for the L1, with all of these implemented in the future.
What We Can Do Today
Until these future enhancements arrive, there are ways to address parallel execution that can be made practical today.
Here are a few, of the numerous approaches people have thought about achieving concurrency:
a) UTXO based blockchain - This is much easier because a UTXO spending
transaction has the unspent outputs (which are also signed) as
inputs for every transaction, and that makes it easy to identify
the storage slots that are going to be affected.
b) Speculative concurrency - Attempt executing every transaction in
parallel, transactions with conflicts are scheduled at the end.
c) Speculative concurrency with role-based separation of nodes - Some
nodes participate in ordering (e.g., grouping transactions
together) and some execute.
d) Storage access lists provided as an input for transactions - To help
identify what storage (or which contracts) the transaction will
access.
e) Predicting access lists or speculatively generating and caching
(e.g., estimateGas).
f) Static analysis of contracts or bytecode analysis to determine
access lists ( e.g., commutative operations, even with collisions,
can produce a correct state).
At a high level, all of the following (except UTXO) fall into one of
these two groups*:
Speculative concurrency
Access Lists
* there are certain methods (apart from the list above) that may not fall into either group, but the above classification is good enough for most approaches
Discussing Different Approaches to L2 Parallelization
Let's continue to assess each of these groups, and find out what each of these approaches could mean for an EVM compatible Layer2, but before that, I bet you are thinking - what about the UTXO model?
Discussion:1 Give away EVM compatibility/equivalence
A chain/L2 based on the UTXO model is easier to parallelize than an account based model. In the former, a transaction is generally a spending transaction and includes the unspent outputs that it is willing to spend (along with proper signatures of the inputs) for the transaction to be valid. This provides for a perfect opportunity to group together transactions that do not spend the same inputs, and execute them in parallel.
However, a chain based on UTXO model isn’t EVM equivalent, and loses out on the advantages of the existing Ethereum toolset, code and developers.
Fuel, Findora are some of the popular examples today, which enforce parallelization and utilize a UTXO model.
Additionally:
The UTXO model can be extended to have parallel validation with
utreexo-
[https://blog.bitmex.com/faster-blockchain-validation-with-utreexo-accumulators/]
And, there are some chains that use both UTXO and account model like
Findora
[https://wiki.findora.org/docs/modules/prism/Overview/]
Smart contracts with UTXO account model and parallelization is also
possible
[https://forum.celestia.org/t/accounts-strict-access-lists-and-utxos/37]
But, even considering the successful implementation of these possibilities, the chain would still not be EVM equivalent.
Going back to the two groups we previously agreed upon, let’s discuss each of them in more detail-
Discussion 2: Speculative Concurrency
Speculative Concurrency appears to be a very popular strategy for parallel execution. A lot of research has been done, lots of ideas shared and several optimizations to speculative concurrency have been proposed.
The general idea of speculative concurrency is to execute transactions in parallel threads speculatively. If there were collisions (common state access) between these transactions, they are discarded and rerun sequentially later.
Adding on to this general idea, there have been several proposals towards improving Speculative concurrency such as - ‘Separation of nodes with speculative concurrency’ - which involves distributing the network into nodes, who have separate roles - mainly a distinction between those that participate in ordering and some that execute
For ex -
[ParBlockchain],
[Rainblock]
(Validator nodes, IO nodes), Flow from Dapper Labs (separation of
consensus and compute)
[‘BlockSTM’] is
another proposal that is ‘built around principles of Software
Transactional Memory’. It increases efficiency through dynamic
dependency estimation and a smart scheduler.
Some other ideas further add to this with dependency graphs, locks and
static/bytecode analysis.
[Forerunner]
produces constraints based on multi future predictors and speeds
execution through the constraints.
But, while there are various proposals, it is challenging to accurately
evaluate its effectiveness in practice.
The current concerns with Speculative concurrency have been:
It involves a lot of aborting tx and re-executing - which brings in
the need for pricing, otherwise this could open up to DoS attacksSeveral of these methods might include changes on a protocol level
Speculative concurrency can suffer from penalties if a lot of tx
have conflicts and have to be scheduled again.If the execution time of one tx in a batch is significantly more
than the others, speculative concurrency will yield only minor
benefitsIt also depends on the activity of the network, types of
transactions and the size of the chain among other things, which
are hard to generalize, so the efficiency might not be
deterministic
‘An Empirical Study of Speculative Concurrency in Ethereum Smart Contracts’ by Seraph et al (https://arxiv.org/pdf/1901.01376.pdf) is a great work of analysis on general speculative concurrency (without additional improvements) and its performance.
Some of their results have been “directly quoted” here:
When txs are optimistically executed, conflict grows as blockchain
is more crowded, generally 35% clash rate“Accurate static conflict analysis may yield a modest benefit”
“In high-contention periods, most contention resulted from a very
small number of popular contracts”“Today, contract writers have no motivation for avoiding such
conflicts. It could be productive to devise incentives, perhaps in
the form of reduced gas prices, for contracts that produce fewer
data conflicts.” (we will discuss about this under method access
boundaries)“Speculative techniques typically work well when conflicts are
rare, but perform poorly when conflicts are common”
The results of speculative concurrency could indeed be subjective, but to still find an estimation of the effects such a model could have - lets try looking back!
Approximating efficiency of general speculative concurrency through the eyes of an actively operating L2:
[Boba Network] is an Optimistic Rollup with a considerable size (record) of transactions ranging throughout a year. It houses several defi dapps, games, tokens, hybrid compute applications which brings in a variety of types of transactions and thus is a suitable candidate for the L2 whose eyes we want to borrow.
From these past records of transactions on the network, we tried to extract information pertaining to each (transaction), namely the storage accesses (read/write) in the hopes of estimating what efficiency speculative concurrency, if it were to exist, would bring to the network.
The results, that follow, are based on around 10,000 transactions from Boba’s history around block ranges (365k-370k) and (795k-800k). While the range is an indicator for expected behavior, there is scope for varying the ranges and comparing the results.
Boba, as is the case with Optimistic Rollup design, does not have a mempool currently that could clearly reveal the collisions based on the execution time by the sequencer. For approximation, transactions with close proximity have been grouped together (in groups of 3 and 5) as an estimate of what mempool/ concurrent transactions could look like (in the future).
Furthermore, collisions at two different levels have been represented distinctly:
i) Collisions at a contract access level (i.e. two or more transactions
that access the same addresses)
ii) Collisions at the storage level to check exact parallelizability
(i.e. two or more transactions that access the same storage slots of
these addresses)
The storage access information from these historical transactions also include operations on the storage slots that each transaction performs.
Between two transactions (tx1, tx2) and their operations on a specific storage slot-
(read, read) - works for concurrency
(read, write) and (write, read) - does not
(write, write) - mostly does not, unless operations are commutative

*Total groups: number of groups of txs, (approximate grouping around proximity of tx - think blocks)
*Collision addresses: Groups that have collisions based on the addresses they access
If two or more txs in a group access a common addresses, we treat the group for having address collisions
Collision Storage slots: Groups that have collisions based on the storage slots of addresses they access. If two or more txs in a group access the same slots in the same addresses, we treat the group for having storage slot collisions*
Results from both of these block durations show that conflicts could be expected to be quite common (in this case), and general speculative concurrency (without improvements), though absolutely worth trying, could yield uncertain results.
Discussion 3: Parallel execution with Access Lists
Access lists for parallel execution, proposed with ‘Easy parallelizability’ ([https://github.com/ethereum/EIPs/issues/648]) is one of the other lines of thinking about the problem. This involves creating a new tx type that allows users to specify the addresses and storage slots a transaction will access (read/write), as a part of the transaction object. The transactions which have disjoint sets can then be executed in parallel.
Solana utilizes a system similar to access lists to enable parallel execution - [SeaLevel] - where storage access info is embedded into the transaction as instructions (address and operation) to prefetch them for execution, [Sui] has a similar approach to Solana.
The main problem with access lists is the difficulty of knowing which states and slots a transaction would affect in advance, without executing the transaction. There exists rpc endpoints like eth_createAccessLists ([https://geth.ethereum.org/docs/rpc/ns-eth#eth_createaccesslist]) which simulates to estimate access lists based on the state of the prior block. Static analysis of bytecode could also be effective in predicting access lists for a tx ([https://github.com/alexchenzl/predict-al])
Based on current community discussions and strategies, access lists appear to be the most promising and effective approach for enabling concurrency in the EVM. The usage of Access lists would typically not involve modifying the EVM or adding an additional layer to achieve the goal. Furthermore, it is closer to and can gain from several ongoing research efforts like Ethereum’s Statelessness/Witnesses generation, which can be very close to obtaining strict access lists. Optional Access lists ([https://eips.ethereum.org/EIPS/eip-2930]) ([https://eips.ethereum.org/EIPS/eip-2929]) is already enforced on L1 allowing to prefetch states on the basis of optional access lists (although not for parallelization).
But in order to implement parallel execution, access lists have to be made strict - they should be maximally complete, so as to know exactly which transactions can be executed concurrently in parallel and avoid penalties for clashes while execution.
Currently Ethereum has ‘Optional Access Lists’ implemented through a new Tx type. But is it possible to make this a compulsion (strict) and enforce concurrency on the network? The assumptions are - a) toolset/libraries/rpc endpoints for the new tx type exists, but several of the most popular user wallet do not support the tx type yet, and at least some wallet will remain without support b) Users do not know or do not want to generate access lists or use scripts for sending txs. Furthermore, it is very difficult to know which states and slots a tx would affect without executing the transaction.
Broadly, the questions that must be answered for enforcing access lists are-
How to generate an almost correct and complete access list?
Who generates access lists for the users?
What if wallets add support for the tx-type? How do we still go from ‘optional’ to ‘strict’ access lists and enable parallelization on L2?
If wallets were to enable the new transaction type, they might use `eth_createAccessList` to estimate the access list for the transaction. But, there is a possibility that this access list will not be accurate when the transaction is actually executed (since estimation would involve using a prior older state). And as per the demand, for transactions with strict access lists, any transaction with incomplete or incorrect (optional) access lists may be either reverted or queued to be executed sequentially. We could however still utilize Ethereum’s existing transaction types without having to create a new one, although,
It is important to maintain the distinction between the original "optional" element for prefetching states and the "strict" element where a transaction can be reverted if it does not provide a complete access list.
As a solution, an opt-in mechanism with a precompile on the network can be made use of to switch between optional (default) and strict (parallelization) choices for each user. Subsequently, when a user's access list choice is set to ‘strict’, any access outside the specified list should be unsuccessful.
Two Proposals:
But, Irrespective of whether tools exist for the generation of access lists, the question remains: can we do more?
Here are two proposals.
Proposal 1: Method Access Boundaries
It is common for most transactions on a blockchain to primarily involve only a few types of smart contracts. If each transaction includes additional data in the form of access lists, it is likely that there will be repeated patterns of similar access lists with similar calls to contracts.
For a new line of thought, contracts themselves could be the ones to specify access lists, instead of the transaction sender in some cases. In other words, transactions are directed to accounts, and these accounts may have internal calls to other accounts. (we are interested in contract accounts only, since transactions from EOAs to EOAs already have all the information to parallelize), If each contract, on this chain of calls - were to have their own method access boundaries (meaning) - “could bound the addresses that each of the methods in the contract are able to access” (indefinite is a valid option) - we could be closer to finding out intersections and storage collisions between transactions before they are executed.
In addition to being a potential way to execute transactions concurrently, pre-specified method access boundaries could also be a way to enforce higher security standards for a contract by dictating what external methods/addresses a contract is allowed/supposed to call.
Several contracts do have complicated logic, there are contracts (or methods) that allow arbitrary calls, for instance contract wallets, there are proxy contracts which would not really benefit from method access boundaries (these will have ‘indefinite’ boundaries), but on the other hand a lot of general transactions would. Method Access Boundaries when used in combination with other parallelization techniques could result in an increased efficiency.
The goal is to encourage the creation of contracts that can be maximally parallelizable or have clearly defined method access boundaries, in order to improve scalability at the layer.
One such model including access boundaries is envisioned below.
Specifications:
- Have an optional extra storage layer for storing the access
boundaries of each contract account (specifically definite for
each of the methods of the contract account)
Storage can be optional for nodes. This could also work with multiple sequencers, where some sequencers use this storage layer and could support method access boundaries for parallel execution. In case a user experiences transaction reversions, they could always direct their transactions to a general sequencer (that does not use or understand this extra storage layer).
The method access boundaries could be centrally supplied/generated
by the deployer.
Requirements for a contract to comply can be optional and can be
similar to verifying contracts - plus could be provable.
Contract fuzzing can be potentially utilized to find/prove access
boundariesIn case the method access boundaries are found to be
incomplete/wrong while execution, the sequencer would revert the
transaction (or) queue them to be executed sequentially. A default
route (not involving parallel execution) has to be maintained in
addition such that transaction chains involving those (incomplete)
contracts can be sent through the default route.
The maintained list would not be enough if the addresses it
interacts with, cannot be determined prior execution (delegate
call, arbitrary call etc)This works for transactions that have information about all the
contract accounts involved in the transaction call chain. This is
easiest if the transaction does not involve calls to multiple
unknown addresses. Even one contract without information on the
transaction call stack could fail potential parallelizing
(fortunately, most of the common transactions we see in a network
do not involve such calls to several unknown addresses except that
of the senders).Some access boundaries can have an additional spec - i.e
interactions with them could allow updation to the existing
boundaries of other methods of the contract. - for example, a
method that adds an ‘address’ value to the storage of the account.
The node that keeps track of the storage then, updates the
boundaries when calls are made to such methodsSome methods will not have access boundaries that can be specified -
in which case the external contract addresses in the boundaries
can be specified to be undetermined.
For example, each method could have encoded access boundaries in the form

Where, “Type” determines if these boundaries can be written to, and R/W determines read or write access to external contract
For a further simplified model, only the external contract accesses can be stored for the whole contract - (similar to how comparisons are in Easy parallelizability “v1” [EIP 648] )
for ex with-
tx1 = A -> B -> C
tx2 = E -> F -> D
can both be compared simply by comparing the set, and executed parallelly if there's no intersection
(S{A} U S{B} U S{C}) ∩ (S{E} U S{F} U S{D}) ≠ Φ
[Where S{X} is the method access boundaries of the method X]
Proposal 2: Meta AL Transactions and Account Abstraction
To reiterate one of the problems - people may have access to eth_CreateAccessLists which generates an estimated access list for a transaction (for the use in optional access list)- and conversion from ‘optional’ to ‘strict’ access list has been discussed before. Even with access to an rpc, most of the wallets today do not support an ethereum tx-type with access lists, and furthermore users might not know or want to write scripts for populating transactions with the respective access lists.
Moreover, since existing rpc methods can only give an estimation, users might not be well suited to provide access lists when the requirements are ‘strict’ - but at the same time specialized actors might be able to provide smarter access lists. Meta transactions can be a way to relieve the users from involvement with generation and supply of access lists.
We will start the discussion with meta-transactions (the way we know it) which are suitable for specific contract addresses, and later will move towards generalizing this for all contracts with ‘account abstraction’ methods.
So, to start with, access lists are a part of the tx object - and a relayer can be assigned the duty to add the access lists to a transaction upon forwarding a user signed message. This meta-transaction can then further be sent to the actual contract. Transactions to these contracts can be made cheaper - as incentivization, if they were to develop and have support for Meta AL transactions. This is similar to the gasless meta-transactions that some contracts are designed to support. But this approach isn’t very generalized and works only for contracts that opt-in and want to support parallelizability.
How do we generalize this? i.e allow this for all transactions throughout all contracts
Enter - Account Abstraction
Account abstraction on L2 can enable forming transactions consisting of multiple signers, and custom logic for validating the tx, without the need for users to worry about providing access lists.
Account abstraction enables building custom transaction objects, logic, signature schemes and essentially revamping the kind of transaction/operation a network supports and identifies, easily.
With a new userOp structure and wallet logic, any address would be able to send transactions with the responsibility of providing access lists to a second signer of their choice.
One such model that uses account-abstraction to support crowdsourced (and smart) meta access-lists could be as follows-
Specifications:
Abstract out signature verification and requirements with account
abstraction ERC-4337(modified to include provider
address/signature for each user operation). A smart contract
wallet level abstraction with relayers could also work, but does
not necessarily generalize it.There exists a market of access-list providers whose job is to
provide access lists for transactions. (we can call them providers
in short). Even with access list estimation methods available,
these external providers could be a step more efficient in
providing appropriate access lists. For instance, dapps that also
provide their own provider, might be a preferred choice for
interactions with them.
They are rated/priced at the efficiency with which they can
estimate access lists for transactions (smart providers may
include additional parameters or have their own logic of
computation, such that estimation is accurate most of the times).Based on the customized signing conditions - each user operation
could specify the provider for access lists (or) each account
could set rotating signers for supplying access lists.A user would sign and submit a transaction to the relayer (or) an
operation to their wallet specifying the provider, who in turn is
either specified by the user, or is selected for a specific epochThe relayer/provider then wraps the user tx along with the relevant
access list for the transaction and calls the User Account. The
User Account can then validate the transaction, signatures and
send it forward for execution.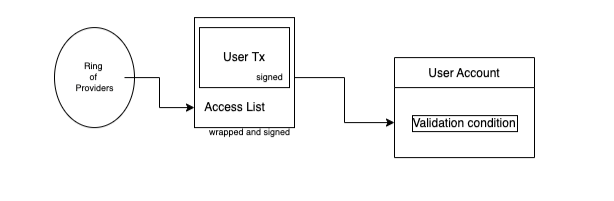
Account abstraction is easier to implement for an L2 than the base Layer, and several L2s would move on to account abstraction at some point. If this can be utilized to enable third party providers/relayers to provide ‘stricter’ access lists, a new market of providers could form. This probably can also be combined with ideas from ‘method access boundaries’, where projects could run their own relayers/providers that could do the job of providing access lists for transactions to their contracts in the most efficient way.
While the Quest for Scalability is never ending, there is a clock thats ticking and will soon reveal a limit to how much networks can be scaled. Considering the current standards, that limit would not be very high. Some techniques such as these, or a combination of several, could in time, be the fuel that keeps the quest for Scalability running, and reset the clock, to delay the worry indefinitely for some time again in the future
So long and thanks for all the fish
But this isn’t the end of exploring the potential of the topic, the intention is to start a conversation
How efficient exactly could these methods be in practice?
How can we make parallel execution deterministic?
Several of these methods depend on existing ecosystem toolsets and
their compatibility. When and what kind of support will be
introduced in the future?How big a change to the UX does this involve?
As we wrap up for today, here are some questions that will come up over and over again, and probably the only way to get the answers will be to attempt implementing. Everyone of course will have different answers, because it truly isn't a one-size fits all problem. But the core of the matter is to acknowledge this as a nuance that can be solved, and take that first step on thinking about this together, today!